
Measuring the environmental footprint of a clothing item requires a lot of data inputs. This includes the materials used, how the materials were made, where they came from, how the product was assembled, and the transportation method that was used, to name a few.
The problem with data collection
It is virtually impossible to have primary data on all these factors. Especially if your supply chain is scattered across the globe, and you only rely on email communication. You can easily fall into the trap of wasting a lot of time collecting primary data without proper prioritization.
The power law: focusing on the important inputs
Luckily, not all of the necessary inputs are of equal importance. There is a power law at play which shows that most of a product’s footprint comes from a few key data points. We’ll dive deeper into this power law in an upcoming article.
The importance of product weight
The weight of a product is probably the most important input when calculating its environmental footprint. It has a direct influence on the amount of material needed, the required packaging, as well as the transportation cost.
Dealing with missing weight data: An inside look at Carbonfact
At Carbonfact, we handle missing weights in the same way as we handle other missing information. Our approach involves utilizing available data whenever possible and carefully selecting appropriate constants when necessary. For weights in particular, we have several imputation methods that we try one at a time, until one works.
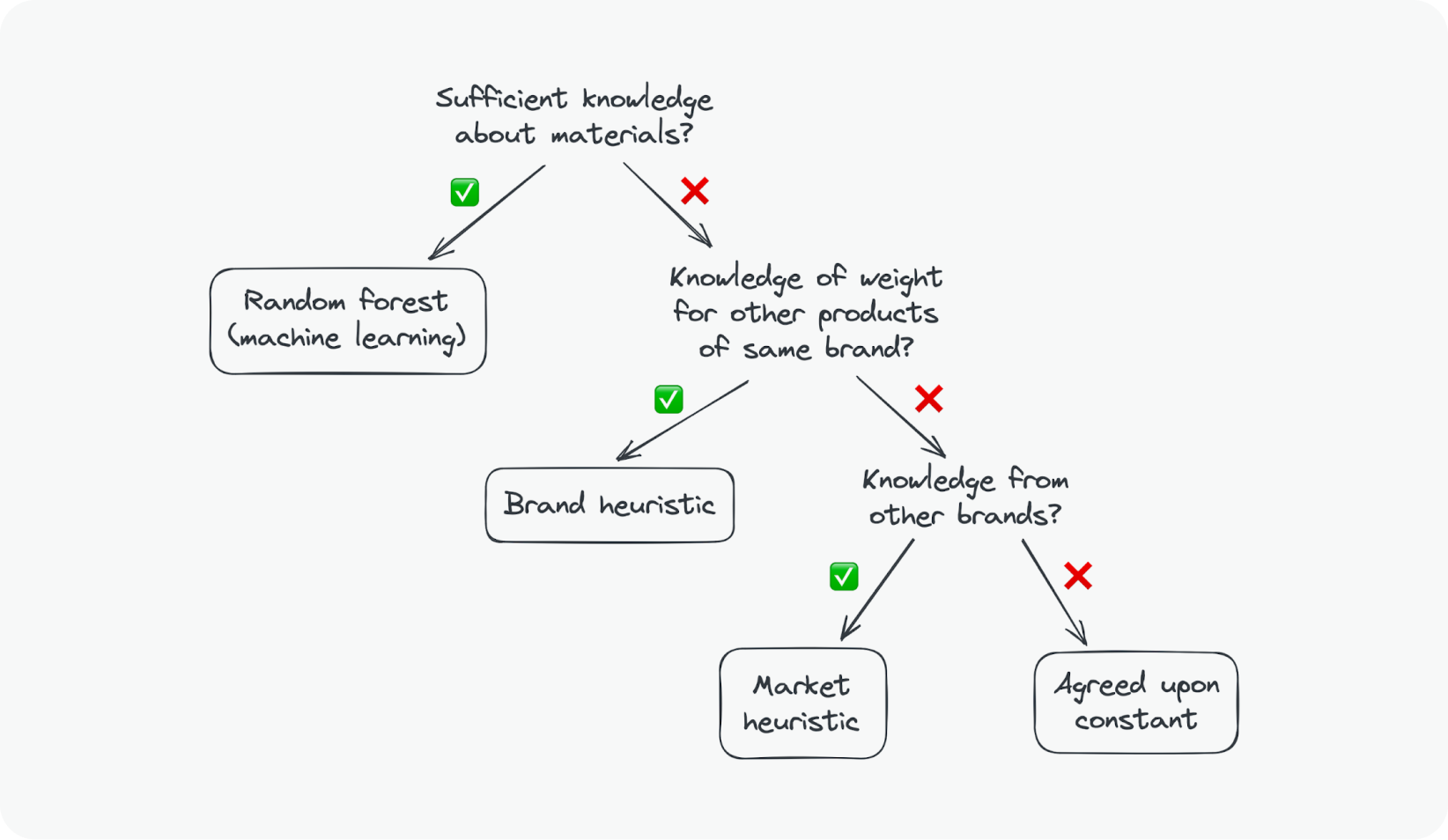
Using machine learning to guess product weights
Our most sophisticated solution involves machine learning. We’ve trained a supervised machine learning algorithm to guess a product’s weight based on whatever information is available. For instance, in the case of shoes, the materials used for the outsole and the upper are strong variables.
Building statistical models with available data
Next, we try to leverage whatever weights are available. For instance, if a customer can provide weights in 50% of cases, then we use that information to build a statistical model. This method can be very simple: if dresses weigh on average 400 grams, with a sufficiently low variance, then that is a good heuristic.
Leveraging existing customer data
If a customer is unable to share specific information, we try to look at what data is available for other existing customers. For example, we’ve accumulated a substantial repository of primary data on underwear.
The last resort: fallback to constant values
Finally, if there is no data, we fallback to constant values from agreed upon databases. On the one hand, as a good source for this is the PEFCR. On the other hand, our customers can also provide us with reasonable values via word of mouth recommendations. In any case, we would choose one, or several, values that would be applied to the whole catalog.
Conclusion: embracing uncertainty
Of course, all of these methods are imperfect in some sense. They all come with an amount of uncertainty. At Carbonfact, we like to keep track of these imputation decisions we make. A scientific way to do that is to quantify the uncertainty that ensues from each decision. For instance, instead of using a single value, we can indicate a product’s weight in a range.
We’ll take a look at uncertainty in the next article. Stay tuned!

